TSP: Temporally-Sensitive Pretraining of Video Encoders for Localization Tasks
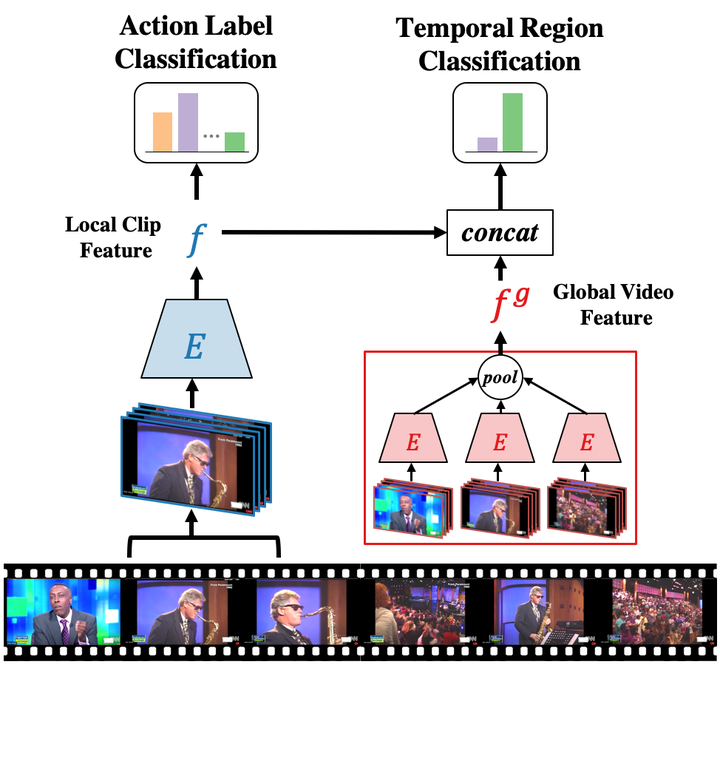 Temporally-Sensitive Pretraining (TSP). We train video encoders to be temporally-sensitive through a novel supervised pretraining paradigm. A fixed-sized clip is sampled from an untrimmed video and passed through the encoder to obtain a local clip feature (blue). A global video feature (red) is pooled from the local features of all clips in the untrimmed video. The local and global features are used to train the encoder on the task of classifying the label of foreground clips (action label) and classifying whether a clip is inside or outside the action (temporal region).
Temporally-Sensitive Pretraining (TSP). We train video encoders to be temporally-sensitive through a novel supervised pretraining paradigm. A fixed-sized clip is sampled from an untrimmed video and passed through the encoder to obtain a local clip feature (blue). A global video feature (red) is pooled from the local features of all clips in the untrimmed video. The local and global features are used to train the encoder on the task of classifying the label of foreground clips (action label) and classifying whether a clip is inside or outside the action (temporal region).
Abstract
Due to the large memory footprint of untrimmed videos, current state-of-the-art video localization methods operate atop precomputed video clip features. These features are extracted from video encoders typically trained for trimmed action classification tasks, making such features not necessarily suitable for temporal localization. In this work, we propose a novel supervised pretraining paradigm for clip features that not only trains to classify activities but also considers background clips and global video information to improve temporal sensitivity. Extensive experiments show that using features trained with our novel pretraining strategy significantly improves the performance of recent state-of-the-art methods on three tasks: Temporal Action Localization, Action Proposal Generation, and Dense Video Captioning. We also show that our pretraining approach is effective across three encoder architectures and two pretraining datasets. We believe video feature encoding is an important building block for localization algorithms, and extracting temporally-sensitive features should be of paramount importance in building more accurate models. The code and pretrained models are available on our project website.
BibTex
@inproceedings{alwassel_2021_tsp,
title={TSP: Temporally-Sensitive Pretraining of Video Encoders for Localization Tasks},
author={Alwassel, Humam and Giancola, Silvio and Ghanem, Bernard},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops},
year={2021}
}